Research Areas
Prof. YANG’s work focuses on prognostic health monitoring and robotics technologies for intelligent safety monitoring in smart cities. Fundamental research studies data-driven condition monitoring of electromechanical equipment in the Internet of Things environment with a focus on multimodal signals processing, intelligent diagnosis, and resilience dynamic monitoring. Critical research on robotics includes machine vision-based perception, 3D shape recognition, and agile robot control for safety monitoring applications.
Research areas include:
- Intelligent Fault Diagnosis and Prognostic Health Management of engineering system
- Safe Service Guarantee of distributed heterogeneous urban equipment
- Machine Learninhg based robot perception and control for safety monitoring
Intelligent Fault Diagnosis and Prognostic Health Management
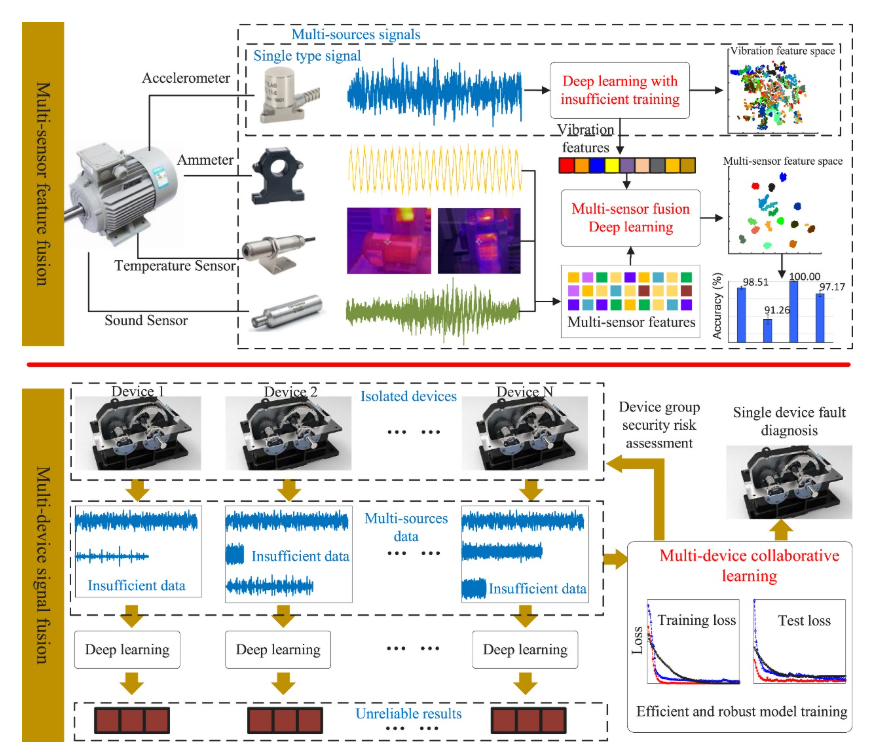
Review of intelligent fault diagnosis for rotating machinery under imperfect data conditions
This study, based on an in-depth analysis of existing methods, proposes a new inductive framework for multi-sensor fusion and builds a multi-platform, multi-sensor experimental setup to collect a rotating machinery dataset covering multiple modalities, devices, operating conditions, and fault types. Compared with existing public datasets, this dataset is larger in scale, more comprehensive in fault categories, richer in monitoring information, and thus of greater research value. In addition, the study reviews recent advances such as graph neural networks, attention mechanisms, federated learning, and transfer learning, systematically summarizes 120 related papers, compares the differences, advantages, and limitations of traditional approaches and deep learning models, and synthesizes the latest progress to inspire future research.
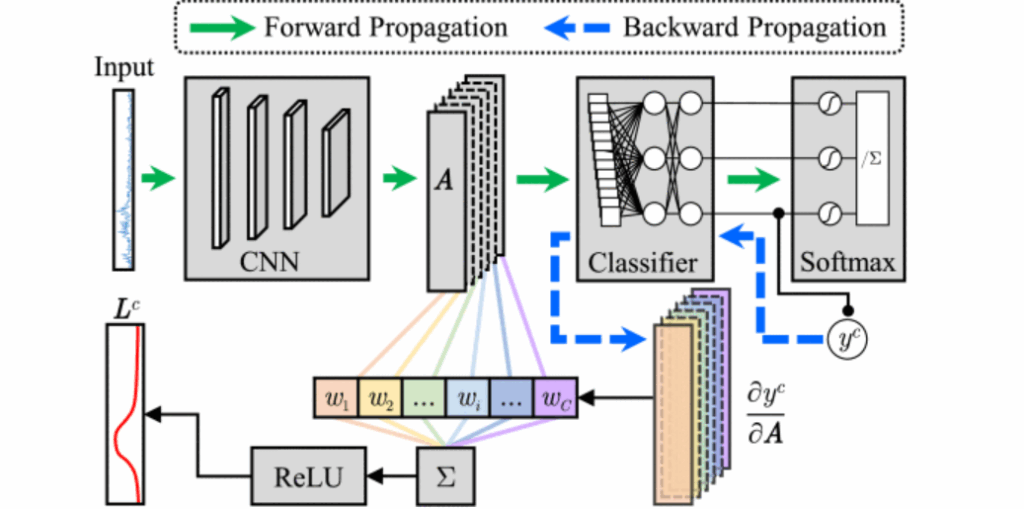
Physical-Knowledge-Guided and Interpretable Deep Neural Networks for Gear Fault Severity Level Diagnosis
Deep-learning (DL) models achieve strong fault diagnosis but lack interpretability. Class activation mapping (CAM) improves transparency without enhancing accuracy. To overcome this, we propose a gradient-weighted CAM–based physically meaningful regularization (PMR) with a two-step backpropagation algorithm, guiding models to focus on relevant frequency bands. The resulting physics-guided models deliver higher accuracy and stronger interpretability, validated on two multi-severity fault datasets.
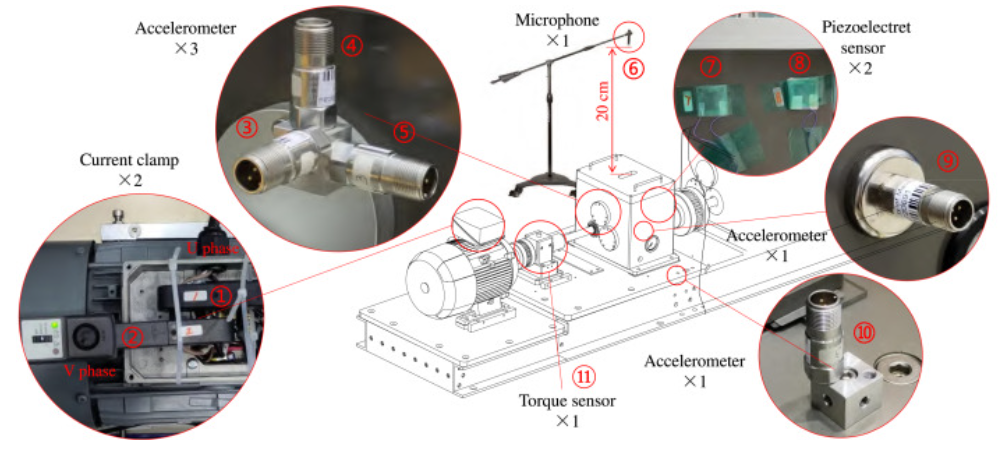
A comprehensive gear eccentricity dataset with multiple fault severity levels: Description, characteristics analysis, and fault diagnosis applications
UM-GearEccDataset is a new gear eccentricity dataset with adjustable fault severity levels, recording 11-channel multimodal signals under diverse conditions. Validated through spectral analysis and deep-learning methods, it provides clear, reliable fault features, offering a solid resource for intelligent fault diagnosis and mechanism studies.
Machine Learning based robot perception and control for safety monitoring
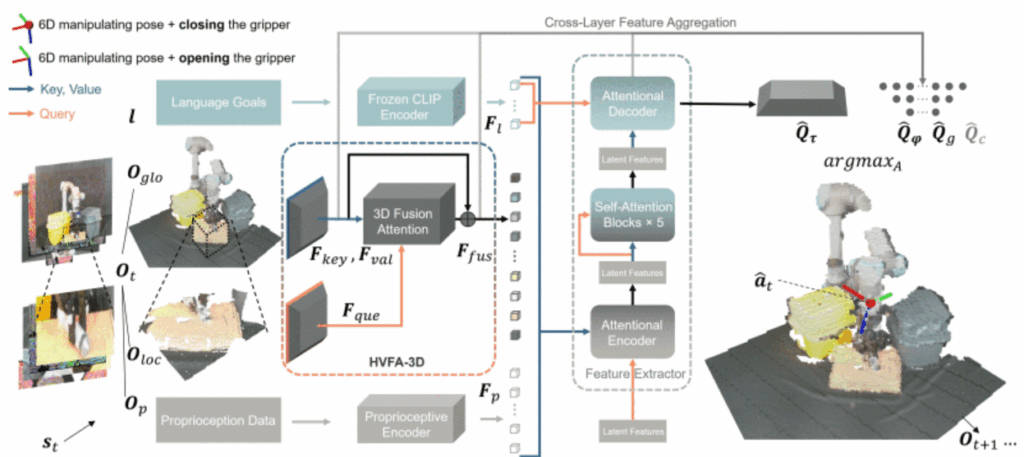
Fusion-Perception-to-Action Transformer: Enhancing Robotic Manipulation with 3D Visual Fusion Attention and Proprioception
Most robot learning relies on images, limiting 3‑D manipulation. We propose FP2AT, combining voxel features, multiscale attention, and proprioceptive encoding with a coarse‑to‑fine strategy. Validated in simulation and real robots, FP2AT achieves superior accuracy and efficiency over state‑of‑the‑art methods.

Robustly solving PnL problem using Clifford tori
The Perspective-n-Line (PnL) problem, which estimates absolute camera pose from 3D–2D line correspondences, is fundamental in computer vision and robotics but is often affected by noise and mismatches. To address this, we propose a robust solution showing that candidate rotations lie on a Clifford torus, with orientation obtained from the intersections of multiple tori and translation solved through linear fitting. This formulation enhances robustness to noise and outliers while simplifying computation. Extensive experiments demonstrate that the method achieves accurate and reliable pose estimation, outperforming existing approaches under challenging conditions.
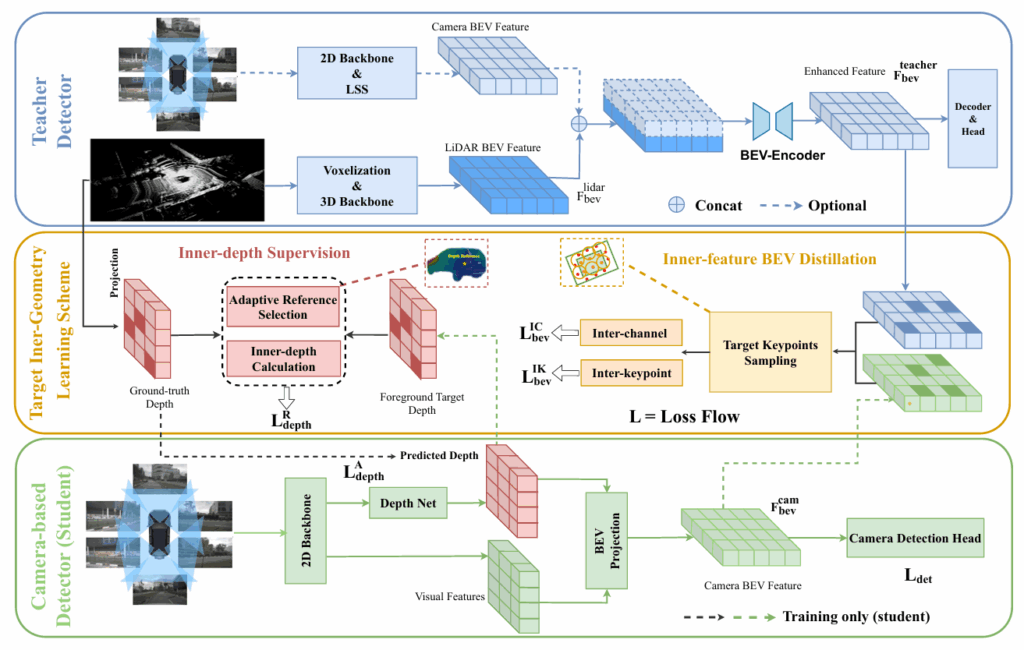
TiGDistill-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning Distillation
Accurate multi-view 3D object detection is crucial for autonomous driving, yet bridging LiDAR–camera representation gaps remains challenging. We propose TiGDistill-BEV, which distills LiDAR knowledge into camera-based BEV detectors via a Target Inner-Geometry scheme. Two key modules are introduced: inner-depth supervision to capture object-level spatial structures, and inner-feature BEV distillation to transfer high-level semantics. Inter-channel and inter-keypoint distillation further reduce domain gaps. Experiments on nuScenes show TiGDistill-BEV achieves state-of-the-art performance with 62.8% NDS, surpassing prior methods.
Research Projects
- Principal Investigator, Research and application of multi-modal sensing and data-driven intelligent process planning technology for industrial robot, Macao Science and Technology Development Fund Key R&D Project, 2020-2023.
- Principal Investigator, Research and Application for Intelligent Detection of Packaging Quality about Semiconductor Devices, Joint research project funded by the Ministry of Science and Technology and the Macao Science and Technology Development Fund, 2024-2026.
- Principal Investigator, Development of a Safety Guaranteed Surgical Navigation System Based on Globally Optimal Registration Algorithm, Macao Science and Technology Development Fund Project, 2023-2026.
- Principal Investigator, Research and application of 3D robotics vision based intelligent self-positioning manufacturing and compliance control, Guangdong Provincial Department of Science and Technology – Special Topic on the Transformation of Hong Kong and Macao Scientific and Technological Achievements, 2023-2024.
- Principal Investigator, Safety evaluation and maintenance management of key on board electromechanical equipment of Rail Transit in Great Bay Area, Guangdong-Guangzhou Joint Fund Guangdong-Hong Kong-Macao Research Team Project, 2020-2024.
- Principal Investigator, Integrated Elevator safety monitoring big data system and application in smart community, UM-Huafa Group Joint Lab Fund, 2022-2025.
- Principal Investigator, Key technologies and applications for robust production of welding equipment, Guangzhou International Science and Technology Cooperation Project, 2023-2025.
- Principal Investigator, Vertical traffic safety monitoring empowers the construction of smart communities, Zhuhai Science and Technology Innovation Bureau Hong Kong and Macao Cooperation Project, 2023-2025.